推荐系统实践(项亮)第三章
第三章 推荐系统冷启动问题
冷启动问题:如何在没有大量用户数据的情况下设计个性化推荐系统?
3.1 冷启动问题简介
冷启动问题(cold start)主要分三类:
- 用户冷启动 对于无行为数据的新用户,如何做个性化推荐
- 物品冷启动 如何将新的物品推荐给可能对它感兴趣的用户
- 系统冷启动 如何在一个新开发的网站(无用户,无用户行为,只有一些物品的信息)上设计个性化推荐系统
一般有以下解决方案:
- 提供非个性化推荐 e.g.,热门排行榜.收集一定用户数据后,再切换为个性化推荐
- 利用用户注册时提供的年龄,性别等数据做粗粒度的个性化
- 利用授权的社交账号导入用户的社交网站上的好友信息,然后给用户推荐其好友喜欢的物品
- 要求用户在登陆时对一些物品进行反馈,收集用户对这些物品的兴趣信息,然后给用户推荐类似的物品
- 对于新加入的物品,可以利用内容信息,将他们推荐给喜欢过类似物品的用户
- 在系统冷启动时,可以引入专家的知识,通过一定的高效方式迅速建立起物品的相关度表
3.2 利用用户注册信息
对于新用户,我们只能推荐一些热门商品,但若知道是一名女性,就能推荐女性都喜欢的物品,即使这种个性化的粒度很粗,每个新注册的女性看到的都是相同的结果.
绝大数网站中,年龄性别都是注册用户的必备信息,还有生日,邮编等.用户的注册信息分三种:
- 人口统计学信息 包括用户的年龄,性别,职业,民族,学历和居住地等
- 用户兴趣的描述 让用户用文字描述他们的兴趣
- 从其它网站导入的用户站外行为数据
如何通过人口统计学信息给用户提供粗粒度的个性化推荐:
- 获取用户的注册信息
- 根据用户的注册信息对用户分类
- 给用户推荐他所属分类中用户喜欢的物品
例如:对于一个28岁的男性物理学家,我们可以查询三张离线计算好的相关表(年龄,性别,职业),分别查询28岁用户,男性,物理学家最喜欢的电视剧,然后将这三张相关表查询出的电视剧列表按照一定权重相加,得到最终的推荐列表.
在实际应用中,可以考虑组合特征,比如将年龄性别看作一个特征.但要注意,使用组合时用户不一定具有所有的特征,因为注册系统并不要求用户填写所有注册项.
从上面的例子可以看出,基于用户注册信息的推荐算法其核心问题是对于每种特征$f$,计算具有这种特征的用户对各个物品($i$)的喜好程度:
$$
p(f,i)=|N(i)\cap U(f)|\ N(i):喜欢物品i的用户集合\qquad U(f):具有特征f的用户集合
$$
在这种定义下,热门的物品会在各种特征的用户中都具有比较高的权重,即高$N(i)$会导致每一类($f$)用户中都有比较高的$p(f,i)$.这又回到本质问题上,推荐系统的首要任务不是推荐热门物品,而是帮助用户发现他们不容易发现的物品.需要找一种新的定义方式来消除$N(i)$的影响,一种自然的想法就是除以$N(i)$
因此,将$p(f,i)$定义为
$$
p(f,i)=\frac{|N(i)\cap U(f)|}{|N(i)|+\alpha}
$$
$\alpha$解决数据稀疏问题,考虑一种情况:某个物品只被一个用户喜欢过$N(i)=1$,刚好这个用户具有特征$f$,此时$p(f,i)=1$,但并无统计意义,因此给分母加上$\alpha$,避免该物品产生较大的比重
刚开始我的想法是
$p(f,i)=\frac{|N(i)\cap U(f)|}{|U(f)|+\alpha}$,但其实这样推荐的还是热门物品,不过是每个特征人群中的热门物品,依然不满足推荐的本质要求.
所以看一个式子会不会受热门物品影响时,看他是否针对$N(i)$处理就行了.
接下来使用Lastfm数据集来验证使用不同的人口统计学特征对预测用户行为的精度的影响,参考代码链接
代码将数据集划分为10份,9训练1测试,在训练集上计算热门程度$p(f,i)=|N(i)\cap U(f)|$,然后在测试集中给每一类用户推荐$p(f,i)$最高的十个物品,并计算准确率和召回率,覆盖率.
按照不同的粒度给用户分类,对比了不同的四种算法
- MostPopoular 推荐最热门的歌手
- GenderMostPopular 给用户推荐和他同性别的用户最热门的歌手(男/女)
- AgeMostPopular 推荐同一个年龄段的歌手,以10岁为一个年龄段
- CountryMostPopular 推荐和用户同一个国家的用户喜欢的歌手
- DemographicMostPopular 给用户推荐和他同性别,年龄段,国家的用户喜欢的歌手
在这个数据集下,结果是粒度越细效果越好,并且国家对精度的影响比年龄和性别的影响更大
3.3 选择合适的物品启动用户的兴趣
解决用户冷启动的另一种方法:对于新用户的第一次访问,不立即给用户展示推荐结果,而是提供一些物品让用户反馈他们对这些物品的兴趣,根据反馈结果进行个性化推荐
问题就是选择什么样的物品让用户进行反馈?一般来说,能够用来启动用户兴趣的物品具有以下特点:
- 比较热门 如果一开始让用户反馈的物品都比较冷门,用户不知道其情节和内容,也就无法做出准确的反馈
- 具有代表性和区分性 启动用户兴趣的物品不能是大众化的,否则不能区分用户个性化的兴趣
- 启动物品集合需要有多样性 冷启动时不知道用户的兴趣,而用户的兴趣可能非常多,因此需要提供具有很高覆盖率的启动物品集合. e.g., 电影网站 Jinni 首先不是让用户选择喜欢哪些电影,而是先让用户选择喜欢什么类型的电影,这样就能很好的保证启动物品集合的多样性
用决策树的方法选择初始物品
决策树的构造根据:
首先给定一个用户集合,作者用这群用户对物品评分的方差度量这群用户兴趣的一致程度.方差越小就说明这群用户的兴趣越一致.
对于物品$i$,将用户分为三类:$N^+(i),N^-(i),\overline {N}(i)$分别表示:喜欢物品$i$的用户集合,不喜欢物品$i$的用户集合,没有对物品$i$评分的用户集合.
令$\sigma_{u\in U’}$为用户集合$U’$中所有用户对物品评分的方差,而$\sigma_{u\in N^+(i)},\sigma_{u\in N^-(i)},\sigma_{u\in \overline {N}(i)}$ 分别表示喜欢物品$i$的用户对其它物品评分的方差, …….通过以下方式度量一个物品$i$的区分度$D(i)$:
$$
D(i)=\sigma_{u\in N^+(i)}+\sigma_{u\in N^-(i)}+\sigma_{u\in \overline {N}(i)}
$$
如果这三类用户集合内的用户对其他的物品兴趣很不一致,说明物品$i$具有较高的区分度.
决策树的构造:
首先从所有用户中找到具有最高区分度的物品$i$,然后将用户分成3类.在每类用户中再找到最具区分度的物品,再分为三类,此时总用户被分为9类,如此进行下去,从而可以通过用户对一系列物品的看法将用户分类.
在冷启动时,可以从根节点开始询问用户对该节点物品的看法,然后根据用户的选择将用户放到不同的分支,直到进入最后的叶子节点,此时我们就已经对用户的兴趣有了比较清楚的了解,从而可以对用户进行比较准确的个性化推荐.
e.g.,

3.4 利用物品的内容消息
之前的用户冷启动关注的是如何给新用户做个性化推荐,而物品冷启动关注的是如何将新的物品推荐给可能对它感兴趣的用户这一问题.显然,物品冷启动在新闻网站等时效性很强的网站中非常重要,因为每时每刻都有新加入的物品,并且要第一时间展现给相应的用户,否则过一段时间,物品的价值就会大大降低.
UserCF算法:
对于大多数网站,推荐列表并不是展示内容的唯一列表,每当一个新物品加入,总会有其他用户通过其他途径看到这些产品并反馈,那么和他历史兴趣相似的其他用户的推荐列表中就有可能出现这种产品,这一过程可以不断进行下去,该物品救恩那个逐步展示到对它感兴趣用户的推荐列表中。
但有些网站的推荐列表可能是用户获取信息的主要途径,此时$UserCF$算法就必须解决第一推动力的问题,即第一个用户从哪发现新的物品.解决第一推动力最简单的方法是考虑利用物品的内容信息,将新物品优先投放给曾经喜欢过和它内容相似的其他物品的用户.
ItemCF算法:
对$ItemCF$算法来说,物品冷启动比较严重,因为其原理是给用户推荐和他之前喜欢的物品相似的物品。$ItemCF$算法每隔一段时间会利用用户行为计算物品相似度,在线服务时会将之前计算好的物品相似度矩阵放在内存中。当新物品加入时,内存中的物品相关表没有该信息,所以无法推荐新物品。解决办法是频繁更新物品相似度表:
基于用户行为计算物品相似度:两个问题:
- 用户行为日志庞大,计算矩阵十分耗时;
- 新用品不展示给用户就无法产生行为日志,也就计算不出包含新物品的相关矩阵。
利用物品的内容信息计算物品相关表,并频繁地更新相关表。
- 我的理解:线上服务时,每当有新的物品,先利用内容相似度推荐物品;到了线下,再利用用户行为日志(此时的用户行为日志是包含了利用内容相似度推荐的新物品的行为日志)计算相似度矩阵,到了下一次线上服务,这些新物品已经在相似度矩阵中了,也就是说不再是新物品,如此循环往复下去。
物品的内容信息多种多样,不同类型的物品有不同的内容信息,如下表:

内容信息(内容相似度):
协同过滤纯粹基于用户的历史行为,跟物品的本身属性,内容没有任何关系,而基于内容则是一句用户的历史行为中操作的过的物品,推荐跟这些物品本身相似的物品。(当然,处理$ItemCF$冷启动时用到了一些内容相似度)
物品的内容可以通过向量空间模型表示,其将物品表示为一个关键词向量.如果物品的内容是一些如导演、演员等实体,可以直接将这些实体作为关键词;但如果内容是文本的形式,则需要对关键词进行抽取。对于中文,首先要对文本进行分词,将字流变为词流,然后从词流中检测出命名实体,这些实体和一些其他重要的词组成关键词集合,最后对关键词进行排名,计算每个关键词的权重,从而生成关键词向量。

对物品d,它的内容表示成一个关键词向量如下:
$$
d_i={(e_1,w_1),(e_2,w_2),…}\qquad e_i是关键词\qquad w_i是关键词对应的权重
$$
可以用TF-IDF公式计算词的权重:
$$
w_i=\frac{TF(e_i)}{logDF(e_i)}
$$
对于电影这类非文本物品,也可以根据演员在剧中的重要程度赋予他们权重。
给定物品内容的关键词向量后,物品的内容相似度可以通过过向量之间的余弦相似度计算:
$$
w_{ij}=\frac{d_i\cdot d_j}{\sqrt{\Vert d_i\Vert \Vert d_j\Vert}}
$$
设文档集合$D$有$N$个物品,每个物品平均由$m$个实体表示,如果两两计算相似度,复杂度过高$O(N^2m)$,因此实际使用中一般通过建立关键词-物品的倒排表加速这一过程。
得到物品相似度后,便可使用$ItemCF$进行推荐。
物品的内容相似度 VS 协同过滤
内容相似度计算简单,能频繁更新,而且能解决冷启动问题,但丢失了一些诸如用户行为中包含的规律,物品流行度等信息。所以一般情况下$ItemCF$的效果更好,但当用户的行为强烈受某一内容属性的影响(例如github中开源项目的作者,人们往往会关注同一个作者的不同项目),内容过滤算法的精度也很高。
向量空间模型在内容数据丰富时可获得比较好的效果,例如长文本的相似度;但文本很短,关键词很少时,该模型就很难计算出准确的相似度。如下例:
“推荐系统的动态特性”和“基于时间的协同过滤算法研究”显然是类似的文章,但是标题中没有一样的关键词。为了解决关键词不同但关键词所属话题相同的问题。首先需要知道文章的话题分布,然后才能准确的计算文章的相似度。话题模型(topic model)的一大重点就是建立文章、话题和关键词的关系。代表性的话题模型有LDA。
LDA(Latent Dirichlet Allocation)
LDA模型对一篇文档的产生过程进行了建模,其基本思想是:一个人在写一篇文档的时候,会首先想这篇文章要讨论哪些话题,然后思考这些话题应该用什么词描述,从而最终用词写成一篇文章。因此,文章和词之间是通过话题联系的。
在使用LDA计算物品的内容相似度时,可以先计算出物品在话题上的分布,然后利用两个物品的话题分布计算物品的相似度。计算分布的相似度可利用$KL$散度:
$$
D_{KL}(p||q)=\sum_ip(i)ln\frac{p(i)}{q(i)}
$$
其中$p$和$q$是两个分布,$KL$散度越大说明分布的相似度越低。
LDA模型:
参考统计学习方法第二版第20章和 LDA数学八卦(Highly recommend)
0.1 文本建模
我们日常生活中总是产生大量的文本,如果每个文本存储为一篇文档,那每篇文档从人的观察来说就是有序的词的序列$d=(w_1,w_2,…,w_n)$
统计文本建模的目的就是追问这些观察到语料库的词序列是如何生成的.我们可以把人类产生的所有语料文本看成是上帝掷骰子产生的,我们观察到的只是上帝玩这个游戏的结果,所以在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,具体就是如下两个问题:
- 上帝都有什么样的骰子 (模型中都有哪些参数,骰子的每个面的概率都对应于模型中的参数)
- 上帝是如何掷这些骰子的 (游戏规则是什么,上帝可能有各种不同类型的骰子,上帝可以按照一定的规则抛掷这些骰子从而产生词序列)
0.1.1 Unigram Model
假设词典中一共有$V$个词$v_1,v_2,…,v_V$,则最简单的Unigram Model就是认为上帝是按照如下的游戏规则产生文本的:

上帝的这个唯一的骰子各个面的概率记为$\vec p=(p_1,p_2,…,p_v)$,所以每次投掷骰子类似于一个抛钢镚时候的贝努利实验,只是贝努利实验中我们抛的是一个两面的骰子,而此处抛的是一个$V$面的骰子,我们把抛这个$V$面骰子的实验记为记为$w\sim Mult(w|\vec p)$
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的

上帝的这个坛子里面,骰子可以是无穷多个,有些类型的骰子数量多,有些类型的骰子少,所以从概率分布的角度看,坛子里面的骰子$p$服从一个概率分布$p(\vec p)$,这个分布称为参数$\vec p $的先验分布。
0.1.2 Topic Model和PLSA
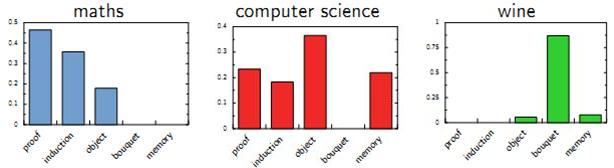
Hoffman 认为一篇文档(Document)可以由多个主题(Topic)混合而成,而每个Topic都是词汇上的概率分布,文章中的每个词都是由一个固定的Topic生成的。下图是英语中几个Topic的例子:
所有人类思考和写文章的行为都可以认为是上帝的行为,那么在PLSA模型中,Hoffman 认为上帝是按照如下的游戏规则来生成文本的:

PLSA模型的文档生成过程可图形化的表示为:
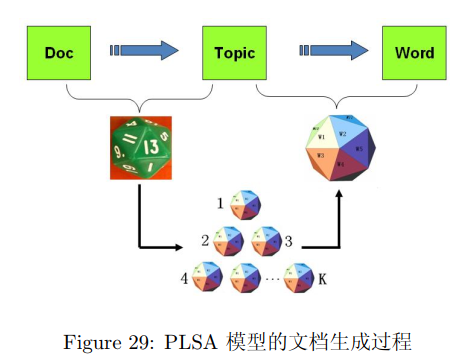
我们可以发现在以上的游戏规则下,文档和文档之间是独立可交换的,同一个文档内的词也是独立可交换的,还是一个bag-of-words模型。游戏中的$K$个topic-word骰子,我们可以记$\vec \varphi_1,…,\vec \varphi_K,$对于包含$M$篇文档的语料$C=(d_1,d_2,..,d_M)$中的每篇文档$d_m$,都会有一个特定的doc-topic骰子$\vec \theta_m$,所有对应的骰子记为$\vec \theta_1,…,\vec \theta_M$,为了方便,我们假设每个词$w$都是一个编号,对应到topic-word骰子的面。于是在PLSA这个模型中,第$m$篇文档$d_m$中的每个词的生成概率为
$$
p(w|d_m)=\sum_{z=1}^Kp(w|z)p(z|d_m)=\sum_{z=1}^K\varphi_{zw}\theta_{mz}
$$
0.2 LDA文本建模
0.2.1 游戏规则
对于上述的PLSA模型,贝叶斯学派显然是有意见的,doc-topic骰子$\vec \theta_m$和topic-word骰子$\vec \varphi_k$都是模型中的参数,参数都是随机变量,怎么能没有先验分布呢?于是,类似于对Unigram Model的贝叶斯改造,我们也可以如下在两个骰子参数前加上先验分布从而把PLSA对应的游戏过程改造为一个贝叶斯的游戏过程。由于$\vec \theta_m$和$\vec \varphi_k$都对应到多项分布,所以先验分布的一个好的选择就是Drichlet分布,于是我们就得到了LDA(Latent Dirichlet Allocation)模型。
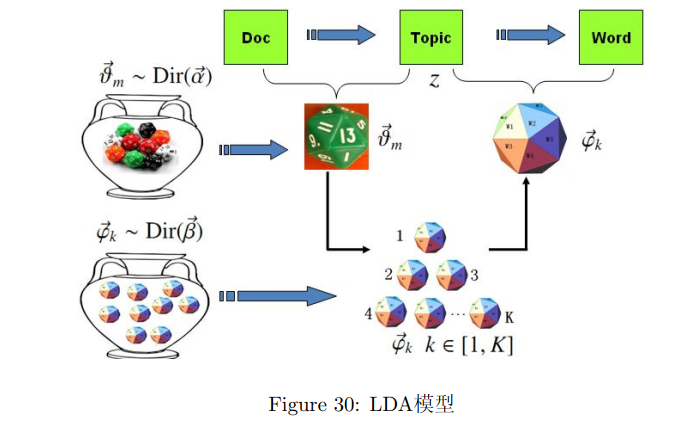
在LDA模型中,上帝是按照如下的规则玩文档生成的游戏的:
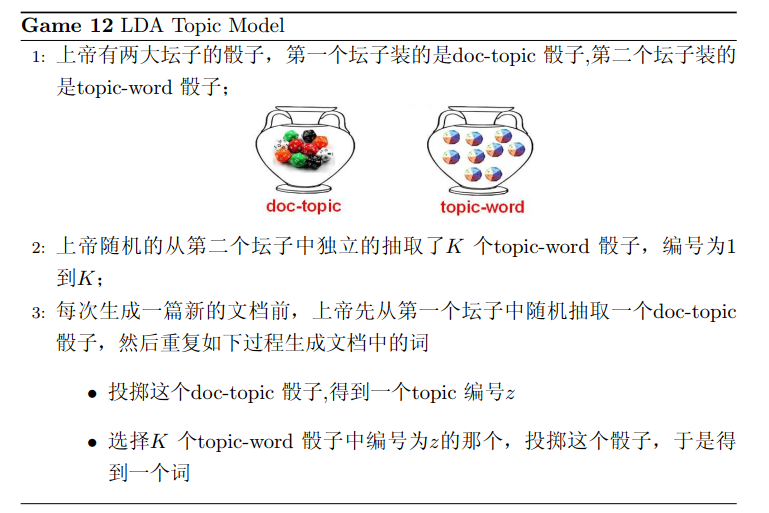
0.2.2 物理过程分解
使用概率图模型表示,LDA模型的游戏过程如图所示:
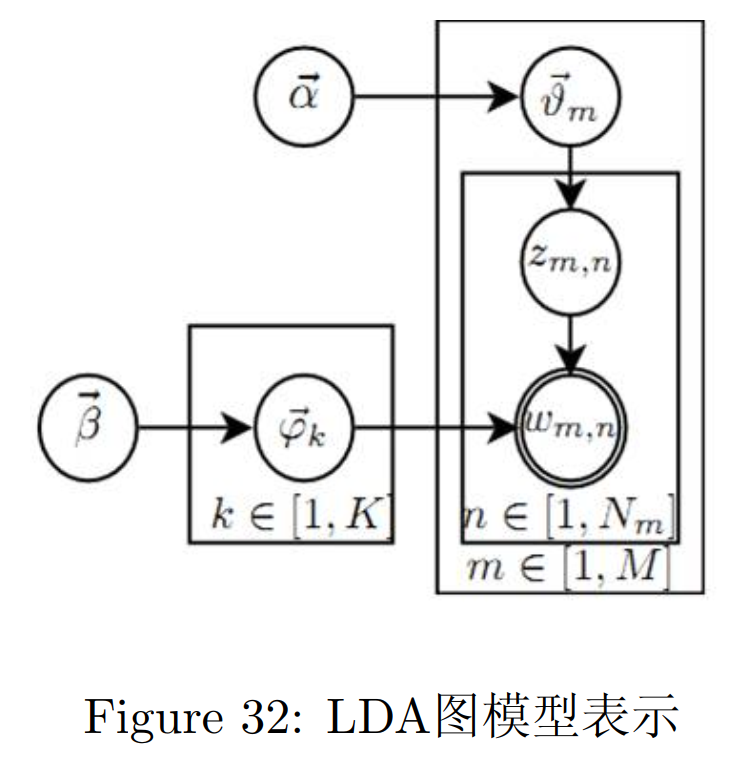
这个概率图可以分解为两个主要的物理过程:
- $\vec \alpha\rightarrow\vec \theta_m\rightarrow z_{m,n}$ 这个过程表示在生成第$m$篇文档的时候,先从第一个坛子中抽了一个doc-topic骰子$\vec \theta_m$,然后投掷这个骰子生成了文档中第$n$个词的topic编号$z_{m,n}$
- $\vec \beta\rightarrow\vec \varphi_k\rightarrow w_{m,n}|k=z_{m,n}$ 这个过程表示用如下动作生成语料中第$m$文档的第$n$个词:在上帝手头的$K$个topic-word骰子$\vec \varphi_k$中,挑选编号为$k=z_{m,n}$的那个骰子进行投掷,然后生成word $w_{m,n}$
$$
\vec \varphi_k=(\varphi_{k1},\varphi_{k2},…,\varphi_{kV})\quad \sum_{i=1}^V\varphi_{ki}=1\\vec \theta_m=(\theta_{m1},\theta_{m2},…,\theta_{mK})\quad \sum_{i=1}^K\theta_{mi}=1\
V:单词个数\quad K:topic个数
$$
玩LDA游戏的时候,上帝是先完全处理完成一篇文档,再处理下一篇文档。文档中每个词的生成都要抛两次骰子,第一次抛一个doc-topic骰子得到topic,第二次抛一个topic-word骰子得到word,每次生成每篇文档中的一个词的时候这两次抛骰子的动作是紧邻轮换进行的。如果语料中一共有$N$个词,则上帝一共要抛$2N$次骰子,轮换的抛doc-topic骰子和topic-word骰子。但实际上有一些抛骰子的顺序是可以交换的,我们可以等价的调整$2N$次抛骰子的次序:前N次只抛doc-topic骰子得到语料中所有词的topics,然后基于得到的每个词的topic编号,后$N$次只抛topic-word骰子生成$N$个word。于是上帝在玩LDA游戏的时候,可以等价的按照如下过程进行:

统计学习方法中的解释:(上面的两张图可以和下图一起食用:)
LDA模型表示文本集合的自动生成过程:首先,基于单词分布的先验分布(狄利克雷分布)生成多个单词分布,即决定多个话题内容;之后,基于话题分布的先验分布(狄利克雷分布)生成多个话题分布,即决定多个文本内容;然后,基于每一个话题分布生成话题序列,针对每一个话题,基于话题的单词分布生成单词,整体构成一个单词序列,即生成文本,重复这个过程生成所有文本。文本的单词序列是观测变量,文本的话题序列是隐变量,文本的话题分布和话题的单词分布也是隐变量。图20.3示意LDA的文本生成过程(详见文前彩图)。
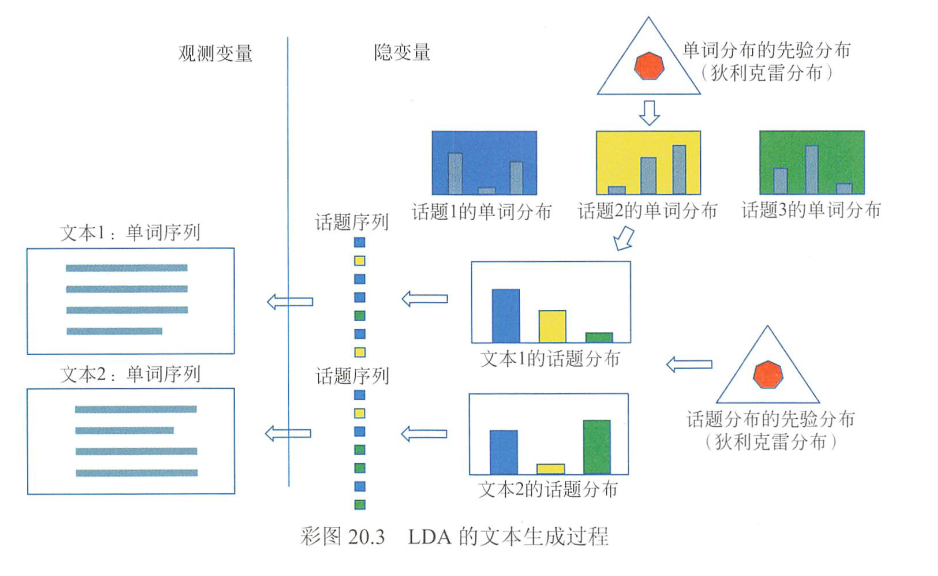
“单词分布的先验分布”对应第二个坛子中骰子的分布;“基于单词分布的先验分布(狄利克雷分布)生成多个单词分布,即决定多个话题内容”对应在第二个坛子抽出$K$个骰子.
“话题分布的先验分布”对应第一个坛子中骰子的分布;“基于话题分布的先验分布(狄利克雷分布)生成多个话题分布,即决定多个文本内容”对应在每次在第一个坛子抽1个骰子,抽$M$次.
0.2.3 Gibbs Sampling
模型的训练和推断在 LDA数学八卦有详细介绍,不再赘述.
3.5 发挥专家的作用
很多推荐系统在建立时,既没有用户的行为数据,也没有充足的物品内容信息来计算准确的物品相似度。因此很多系统利用专家进行标注。
以音乐推荐为例,仅利用歌曲的专辑,歌手等属性信息很难获得较好的歌曲相似度表。因为每个歌手或专辑的好作品只占少部分。因此某公司雇佣一批懂音乐的人,进行了一项称为音乐基因的项目,他们听了几万名歌手的歌,并对这些歌进行各个维度上的标注。最终,他们使用了400多个特征(也被公司称为基因)。因此,每首歌可被表示为一个400维的向量,进而使用向量相似度算法进行推荐。
当然,也可以使用半人工的方式,专家进行标记一定的样本后,使用NLU等技术,通过用户的评论和物品的属性自动标记,也可以设计让用户对基因进行反馈的页面,希望通过用户反馈不断改进电影基因系统。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!