推荐系统实践(项亮)第五章
第五章 利用上下文信息
用户所处的上下文(context)对推荐效果十分重要,例如时间,地点,心情等。推荐系统不能因为用户夏天喜欢过短袖就在冬天也推荐短袖(时间)。当用户在中关街搜索美食时,推荐的美食大部分都是该地点附近的,也能让用户满意。上下文影响兴趣的例子还有很多,例如上班前-下班后、周内-周末等等。因此,准确了解用户的上下文信息是设计好的推荐系统的关键步骤。
本章主要讨论时间上下文和地点上下文,研究如何给用户生成一个TopN推荐列表,该列表包含了用户在某一时刻或某个地方最可能喜欢的物品。
5.1 时间上下文信息
5.1.1 时间效应简介
时间信息对用户兴趣的影响表现在:
- 用户兴趣是变化的 由于用户自身原因发生的变化,例如程序员随着工作时间的增加,从阅读入门书籍到专业书籍。因此准确预测兴趣应该关注用户最近的行为。当然,这只能针对渐变的用户行为,对于突变的用户行为(中大奖),很难预测准确的兴趣
- 物品有生命周期 电影刚上映可能会更受关注。某个物品也可能受新闻事件的影响变得热门或无人问津。不同系统的物品具有不同的生命周期,例如新闻和电影的生命周期短和长。
- 季节效应 除了春夏秋冬带来的影响,节日也是一种季节效应,例如双十一,奥斯卡颁奖礼等,都可以归为季节效应
5.1.2 时间效应举例
略
5.1.3 系统时间特性的分析
给定时间信息后,推荐系统从静态系统变为时变的系统,用户行为数据也变成了时间序列。用三元组$(u,i,t)$代表用户$u$在时刻$t$对物品$i$产生过行为。给定数据集,可通过以下信息研究系统时间特性:
- 数据集每天独立用户数的增长情况 不同网站人数增加/减少的多少、速度和趋势都不一样,因此要首先确定系统的增长情况
- 系统的物品变化情况 有的网站,例如新闻网站,每天会出现大量新的新闻,但周期都不会太长。可以用物品平均在线天数(横坐标可设为流行度),相隔$T$天系统物品流行度向量的平均相似度来度量这些特性。
- 用户访问情况 有的网站人们只访问一次,有的每周来一次……可以统计用户平均活跃天数,或者相隔$T$天来系统的用户重合度度量。
5.1.4 推荐系统的实时性
用户兴趣的变化体现在用户不断增加的新行为中(click、like、收藏等),一个实时的推荐系统需要能够实时相应用户新的行为,让推荐列表不断变化,从而满足用户不断变化的兴趣。
实现推荐系统的实时性,要求:
- 用户行为存取的实时性
- 推荐算法本身的实时性
- 不能每天都给所有用户离线计算推荐结果,然后在线展示前一天计算出来的结果。因此,要求在每个用户访问推荐系统时,都根据用户这个时间点前的行为实时计算推荐列表
- 推荐算法需要平衡用户的近期行为和长期行为,即推荐列表既要反映出用户近期行为所体现的兴趣变化,又不能让推荐列表完全受近期行为的影响,要保证推荐列表对用户兴趣预测的延续性
5.1.5 推荐算法的时间多样性
推荐系统每天推荐结果的变化程度被称为其时间多样性。提高多样性需要分两步解决:
- 首先,保证用户有新行为后,推荐系统能及时调整推荐结果满足用户最近的兴趣,有两种情况:
- 情况一:有的系统会每天离线计算针对所有用户的推荐结果,这类系统无法做到及时调整推荐结果。
- 情况二:实时推荐系统使用的算法不同,具有不同的时间多样性。
- 其次,保证用户没有新的行为时也能经常变化结果,具有一定的时间多样性。有三种思路:
- 生成推荐结果时加入一定的随机性,例如从Top20中随机拿出10个展示给用户,或按照推荐物品的权重采样10个结果展示给用户。
- 记录用户每天看到的推荐结果,然后在每天给用户进行推荐时,对他前几天看到过很多次的推荐结果进行适当地降权。
- 每天给用户使用不同的推荐算法,例如协同过滤,内容过滤等,在用户每天访问时随机挑选一种算法给他进行推荐。
要说明的是,推荐系统首先要保证推荐精度,在此基础上适当地考虑时间多样性。实际应用中需要多次实验才能知道什么程度的时间多样性对系统是最好的。
5.1.6 时间上下文推荐算法
1 最近最热门
最简单的非个性化推荐算法,在原MostPopular的基础上加入时间信息。给定时间$T$,物品$i$最近的流行度$n_i(T)$:
$$
n_i(T)=\sum_{(u,i,t)\in Train,t<T}\frac{1}{1+\alpha(T-t)}\qquad\alpha为时间衰减参数
$$
2 时间上下文相关的ItemCF算法
第二章介绍过的ItemCF算法有两个核心部分:
- 通过用户行为离线计算物品相似度矩阵。
- 预测时,根据用户的行为和相似度矩阵给用户做个性化推荐。
加入时间信息后,需要考虑的变化:
- 物品相似度 用户在相隔很短的时间内喜欢的物品具有更高相似度。
- 在线推荐 用户近期行为更能体现其现在的兴趣,因此在预测时,应该加重用户近期行为的权重,推荐那些和他近期喜欢的物品相似的物品。
ItemCF通过$sim(i,j)=\frac{\sum_{u\in N(i)\cap N(j)}1}{\sqrt{|N(i)||N(j)|}}$计算物品间的相似度。
通过$P(u,i)=\sum_{j\in N(u)\cap S(i,k)}sim(i,j)r_{uj}$计算用户$u$对物品$i$的兴趣。$S(i,k)$是与物品$i$最相似的$k$个物品。
物品相似度计算的改进:
得到时间信息后,物品相似度计算可作如下改进:
$$
sim(i,j)=\frac{\sum_{u\in N(i)\cap N(j)}f(|t_{ui}-t_{uj}|)}{\sqrt{|N(i)||N(j)|}}
$$
$t_{ui}$代表用户对物品$i$产生行为的时间,$f$为数学衰减函数,这里使用$f(|t_{ui}-t_{uj}|)=\frac{1}{1+\alpha|t_{ui}-t_{uj}|}$,如果一个系统用户兴趣变化很快,$\alpha$就应该取较大的值,以增加时间对用户兴趣的影响权重。
预测公式的改进:
由于用户现在的行为和其最近的行为关系更大,采用下式改进:
$$
P(u,i)=\sum_{j\in N(u)\cap S(i,k)}sim(i,j)\frac{1}{1+\beta|t_0-t_{uj}|}r_{uj}\qquad\beta为时间衰减参数
$$
$t_0$是当前时间,$t_{uj}$越接近$t_0$,和物品$j$越相似的物品就会在用户$u$的推荐列表中获得越高的排名。
3 时间上下文相关的UserCF算法
加入时间信息后,需要做以下改进
- 用户相似度 之前的算法中,两个用户相似是因为他们对相同的物品产生过行为。加入时间后,当两个用户同时喜欢相似的物品,他们的相似度应该更高。
- 相似兴趣用户的最近行为 找到和当前用户$u$兴趣相似的一组用户后,这组用户最近的兴趣应该更接近用户$u$当前的兴趣,因此应该给用户推荐和他兴趣相似的用户最近喜欢的物品。
UserCF通过$w_{uv}=\frac{N(u)\cap N(v)}{\sqrt{|N(u)|\cup |N(v)|}}$计算两个用户的兴趣相似度,$N(u)$为用户$u$喜欢的物品集合。
通过$p(u,i)=\sum_{v\in S(u,k)\cap N(i)}w_{uv}r_{vi}$预测用户对物品的兴趣。
用户相似度计算的改进:
$$
w_{uv}=\frac{\sum_{i\in N(u)\cap N(v)}\frac{1}{1+\alpha|t_{ui}-t_{vi}|}}{\sqrt{|N(u)|\cup |N(v)|}}
$$
即两个用户对同一个物品产生行为的时间间隔越远,这两个用户的兴趣相似度就会越小
预测公式的改进:
$$
P(u,i)=\sum_{v\in N(i)\cap S(u,k)}w_{uv}r_{vi}\frac{1}{1+\alpha|t_0-t_{vi}|}\qquad\beta为时间衰减参数
$$
$N(i)$为喜欢物品$i$的用户集合,$S(u,k)$是与用户$u$最相似的$k$个用户。
5.1.7 时间段图模型
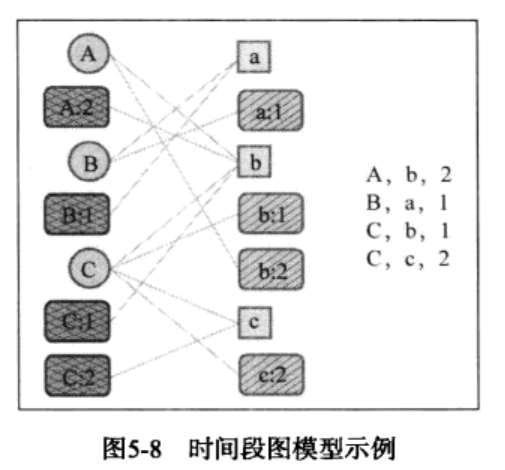
时间段图模型$G(U,S_U,I,S_I,E,w,\sigma)$是一个二分图,$U、I、E$分别是用户、物品、边集合,$w(e),\sigma(e)$分别定义了边、顶点的权重。一个用户时间段节点$v_{ut}\in S_U$会和用户$u$在时刻$t$喜欢的物品通过边相连,一个物品时间段节点$v_{it}\in s_I$会和所有在时刻$t$喜欢物品$i$的用户通过边相连。
其中$E$包含了三种边:
(1)如果用户$u$对物品$i$有行为,则存在边$e(v_u,v_i)\in E$
(2)如果用户$u$在$t$时刻对物品$i$有行为,就存在两条边$e(v_{ut,v_i}),e(v_u,v_{it})\in E$
如下图,用户$A$在时刻2对物品$b$产生了行为,时间段图模型首先会创建4个顶点:用户顶点$A$,用户时间段顶点$A:2$ ,物品顶点$b$,物品时间段顶点$b:2$,然后图会增加3条边,即$(A,b)、(A:2,b)、(A,b:2)$。
最简单的想法是利用PersonalRank算法,但其需在全图上进行迭代计算,时间复杂度比较高。下面为利用路径融合算法来度量两个顶点的相关性。
路径融合算法
一般来讲,图上两个相关性比较高的顶点一般具有以下特征:
- 两个顶点之间有很多路径相连
- 两个顶点之间的路径比较短
- 两个顶点之间的路径不经过出度比较大的顶点
基于此,路径融合算法首先提取出两个顶点之间长度小于一个阈值的所有路径,根据每条路径经过的顶点给这条路径赋予一定的权重,最后将两个顶点之间所有路径的权重之和作为两个顶点的相关度。
路径权重的定义:
假设$P={v_1,v_2,…,v_n}$是连接顶点$v_1$和$v_n$的一条路径,该路径的权重$\Gamma(P)$取决于它所经过的顶点和边:
$$
\Gamma(P)=\sigma(v_n)\prod_{i=1}^{n-1}\frac{\sigma(v_i)\cdot w(v_i,v_{i+1})}{|out(v_i)|^\rho}
$$
$\sigma(v_i)\in (0,1],w(v_i,v_{i+1})\in (0,1]$分别定义了顶点和边的权重,由于$\frac{\sigma(v_i)\cdot w(v_i,v_{i+1})}{|out(v_i)|^\rho}\in (0,1]$,因此路径$n$越长,$\Gamma(P)$越小;如果路径经过了出度大的顶点,$\Gamma(P)$也会变小。这里的$\rho$应该是超参数,其值越大,出度大的顶点对整条路径的影响越大,即$\Gamma(P)$越小。
顶点之间相关度的定义:
得到路径权重后,对于顶点$v$和$v’$,令$p(v,v’,K)$为这两个顶点间距离小于$K$的所有路径,则这两个顶点间的相关度可定义为:
$$
d(v,v’)=\sum_{P\in P(v,v’,K)}\Gamma(P)
$$
对于时间段图模型,所有边的权重都定义为1,即所有$w(v_i,v_{i+1})=1$,而顶点的权重$\sigma(v)$为:
$$
\sigma(v) =
\begin{cases}
1-\alpha & v\in U \
\alpha & v\in S_U\
1-\beta &v\in I\
\beta & v\in S_I
\end{cases}
$$
$\alpha,\beta\in(0,1]$是两个参数,控制不同顶点的权重。路径融合算法可以基于图上的广度优先搜索算法实现。
5.1.8 离线实验
对每一个用户,将物品按照该用户对物品的行为时间从早到晚排序,然后将用户最后一个产生行为的物品作为测试集,并将这之前的用户对物品的行为记录作为训练集。
$$
Recall@N=\frac{\sum_u|R(u,N)\cap T(u)|}{\sum_u|T(u)|}\
Precision@N=\frac{\sum_u|R(u,N)\cap T(u)|}{\sum_u|R(u,N)|}
$$
对于时效性很强的数据集,用户兴趣的个性化不明显,即每天最热门的物品已经吸引了绝大多数用户的眼球,而长尾中的物品很少得到用户的关注。
5.2 地点上下文信息
基于位置的推荐算法
这里介绍LARS(Location Aware Recommender System,位置感知推荐系统),这是一个和用户地点相关的推荐系统。
该系统将物品分为有空间属性的物品(e.g., 餐馆、景点、商店)和无空间属性的物品(e.g.,图书、电影);将用户也分为有空间属性的(e.g., 比如给出了国家、城市、邮编)和无空间属性的。
使用的数据集有三种形式:
- (用户,用户位置,物品,评分)(e.g.,MovieLens)
- (用户,物品,物品位置,评分) (e.g.,Dataset—FourSquare)
- (用户,用户位置,物品,物品位置,评分)
研究员通过分析,发现用户兴趣和地点的两种特征:
- 兴趣本地化——不同地方的用户兴趣存在很大区别
- 活动本地化——用户往往在附近的地区互动
对于第一种数据集(用户,用户位置,物品,评分)——(LARS-U):
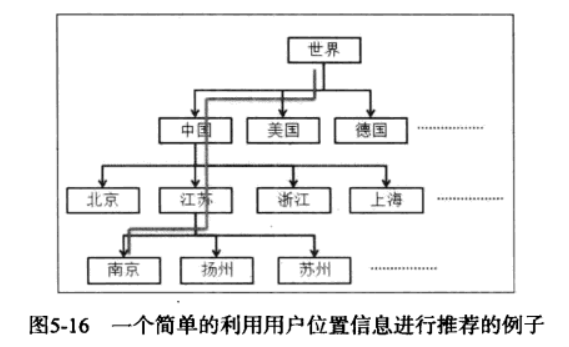
LARS基本思想是将数据集根据用户的位置划分很多子集,因此数据集会被划分为一个树状结构。在每个叶子结点上通过ItemCF给用户进行推荐。
可能的问题是叶子结点上的用户数量过少,行为数据过于稀疏,从而无法训练出好的效果。因此可以从根节点出发,利用每个中间节点上的数据生成推荐列表,最后将每个节点的推荐列表进行加权得到最终结果。一般将这种算法成为金字塔模型(LARS-U),显然,深度是该算法的重要指标。
如下例:假设有一个来自中国江苏南京的用户。我们会首先根据所有用户的行为利用某种推荐算法(假设是ItemCF)给他生成推荐列表,然后利用中国用户的行为给他生成第二个推荐列表,以此类推,我们用中国江苏的用户行为给该用户生成第三个推荐列表,并利用中国江苏南京的用户行为给该用户生成第四个推荐列表。然后,我们按照一定的权重将这4个推荐列表线性相加,从而得到给该用户的最终推荐列表。
对于第二种数据集(用户,物品,物品位置,评分) ——(LARS-T):
LARS首先忽略物品的位置信息,利用ItemCF算法计算用户对物品的兴趣$P(u,i)$,但最终物品在用户的推荐列表中的权重为:
$$
RecScore(u,i)=P(u,i)-TravelPenalty(u,i)
$$
这种考虑了TravelPenalty的算法简称为(LARS-T)。$TravelPenalty(u,i)$代表物品$i$的位置对用户$u$的代价,在物品$i$和用户$u$之前评分的“所有物品”间,计算距离的平均值(或最小值)。使用欧氏距离简单但不实际,因此比较好的度量方式是利用交通网络数据将人们需要走的最短距离作为距离度量。
上式有一个问题:当一个用户仅在海淀区、西城区活动,有必要向他推荐浦东新区的物品吗?换句话说,$RecScore(u,i)$中$i$的范围应该是全部商品吗?
为了避免计算用户对所有物品的$RecScore$,LARS在计算用户$u$对物品$i$的兴趣度$RecScore(u,i)$时,首先对用户每一个曾经评过分的物品(一般是餐馆、商店、景点),找到和他距离小于一个阈值$d$的所有其他物品,然后将这些物品的集合作为候选集,然后再利用上面的公式计算最终的$RecScore$。
对于第三种数据集(用户,用户位置,物品,物品位置,评分) :
由其定义可知,它相对于第二种数据集增加了用户当前位置这一信息,因此我们应该保证推荐的物品距离用户当前位置比较近,在此基础上再通过历史用户行为推荐离他近且他会感兴趣的物品。
5.3 总结
Koren的Collaborative Filtering with Temporal Dynamics系统总结了各种使用时间信息的方式,包括考虑用户近期行为的影响,考虑时间的周期性等。
Neal Lathia在TemporalDiversityinRocommenderSystoms一文中深入分析了时间多样性对推荐系统的影响。他的EvaluatingCollaborativeFilteringOverTime论述了各种不同推荐算法是如何随时间演化的。
如果要系统地研究与上下文推荐相关的工作,可以参考AlexanderTuzhii的工作,他的团队对上下文推荐问题进行了深人研究。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!